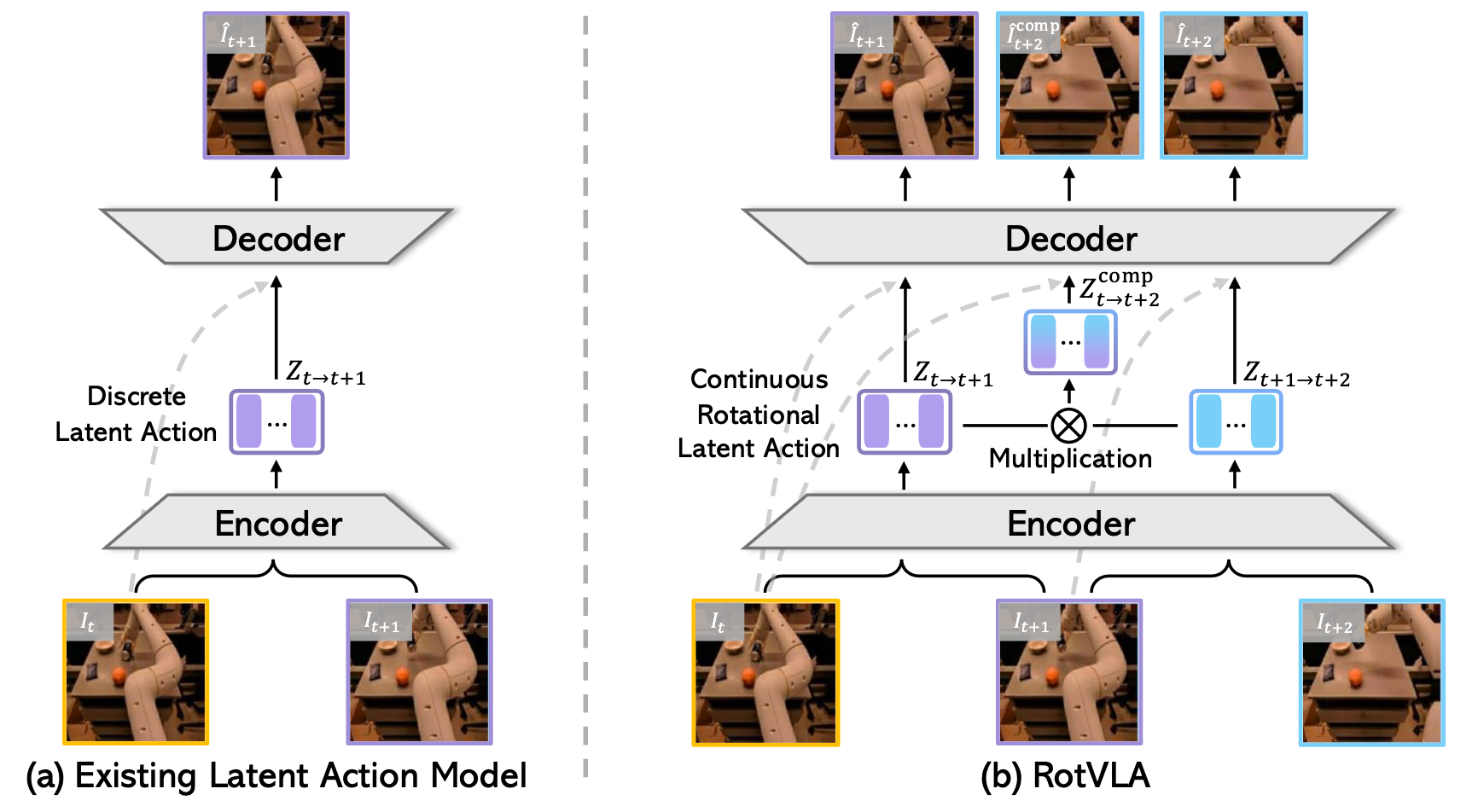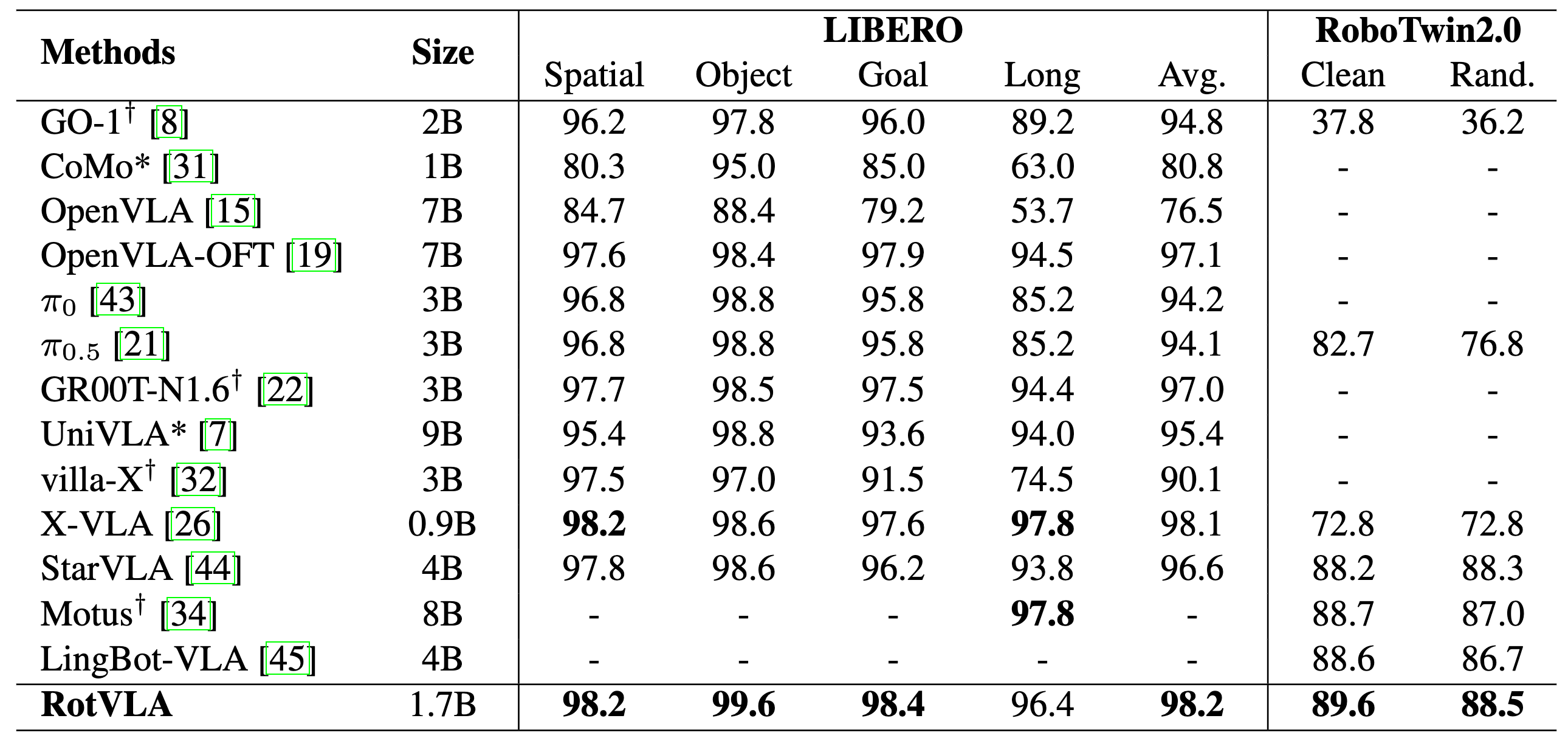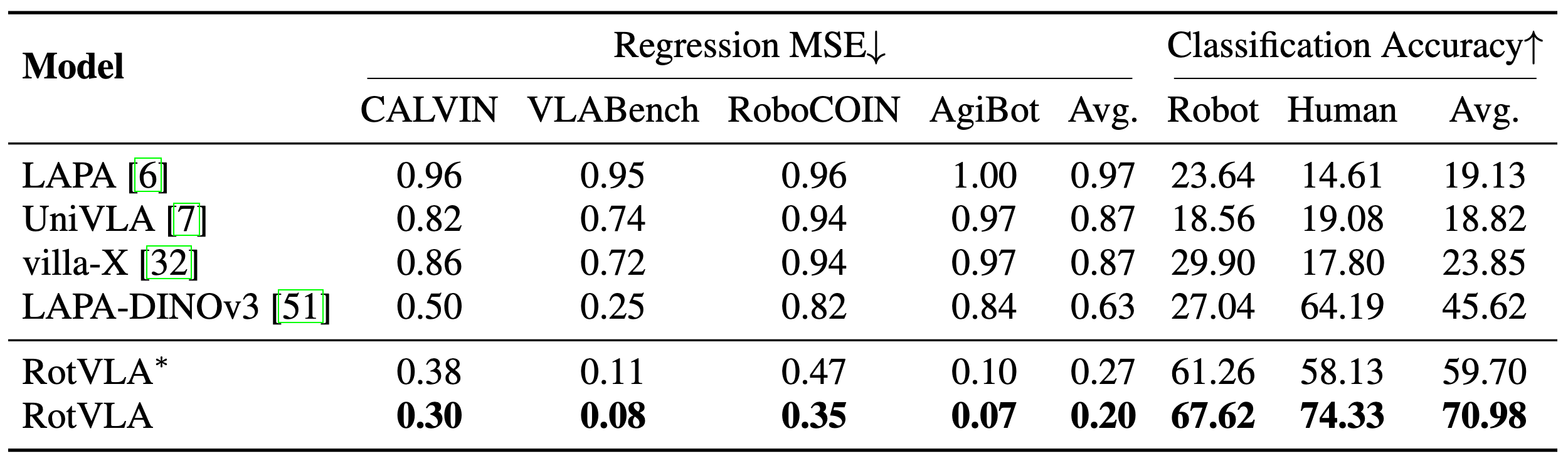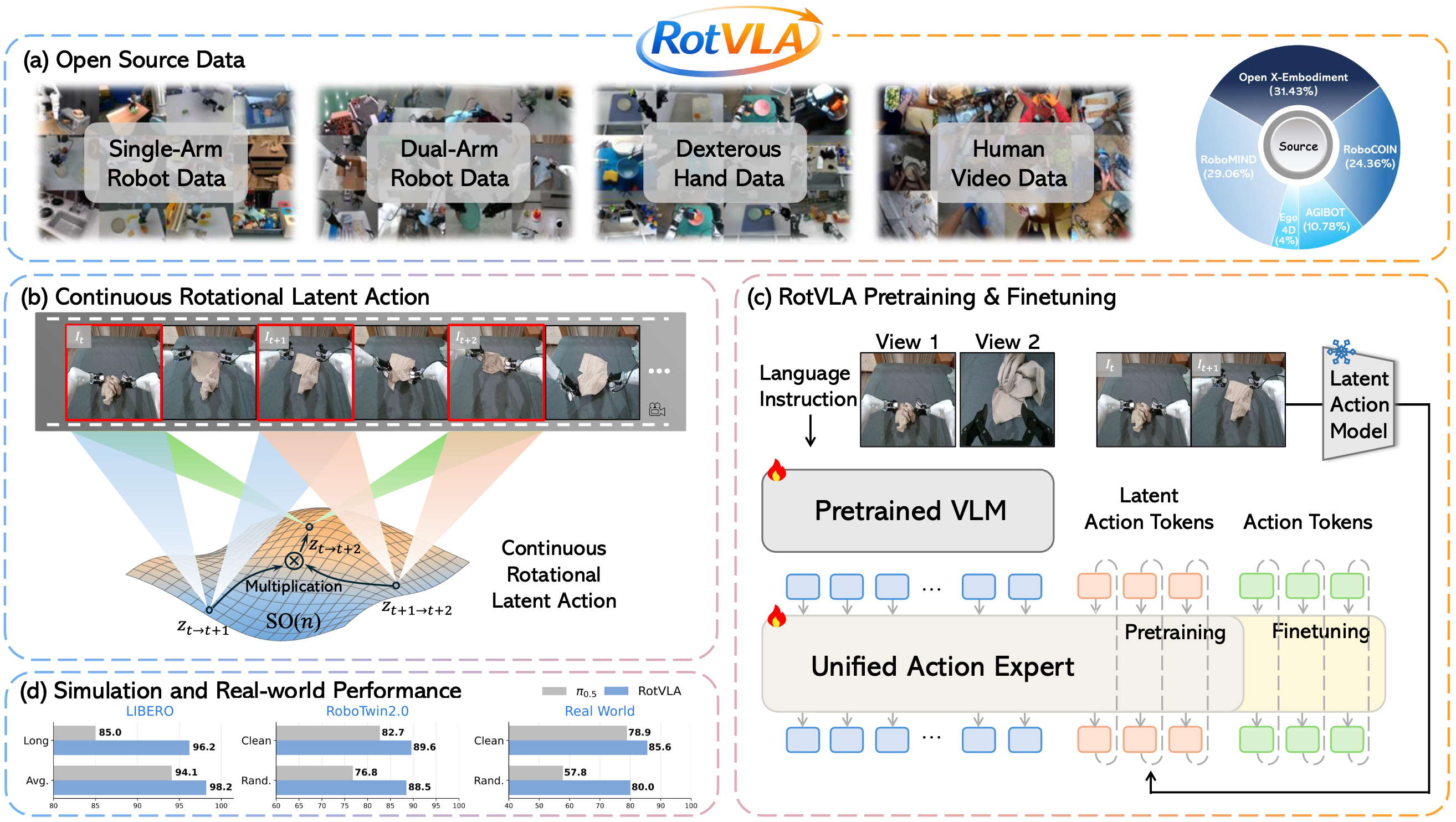
RotVLA instead represents each latent action as an element of the rotation group SO(n). This preserves continuity (using SoftVQ rather than hard quantization) while enabling meaningful action composition through matrix multiplication, mirroring how real-world motions compose.
To prevent the LAM from degenerating into trivial frame reconstruction, we introduce a triplet learning objective. Given three consecutive frames It, It+1, It+2, the model extracts two single-step latent actions and composes them via matrix multiplication to predict the two-step transition. This compositional supervision forces the encoder to capture true motion dynamics rather than copying frame appearance, and generalizes zero-shot to unseen datasets and embodiments.